고정 헤더 영역
상세 컨텐츠
본문
이번에 내가 학습한 내용은 Chapter3의 회귀 알고리즘과 모델 규제이다.
이 중 K-최근접 이웃 회귀(K-nearest neighbor regression)과 선형 회귀(linear regression)을 공부하고 colab 환경에서 실습까지 해보았다.
먼저 k-최근접 이웃 회귀는 KNN 알고리즘을 사용하여 회귀 문제를 해결한다. 여기서 회귀는 임의의 수치를 예측하는 것으로 타깃값도 임의의 수치가 된다. KNN 알고리즘은 가장 가까운 이웃 데이터를 찾을 수 있는데 여기서 이 데이터들(타깃값)을 평균으로 계산하여 예측을 수행하는 것이 K-최근접 이웃 회귀이다.
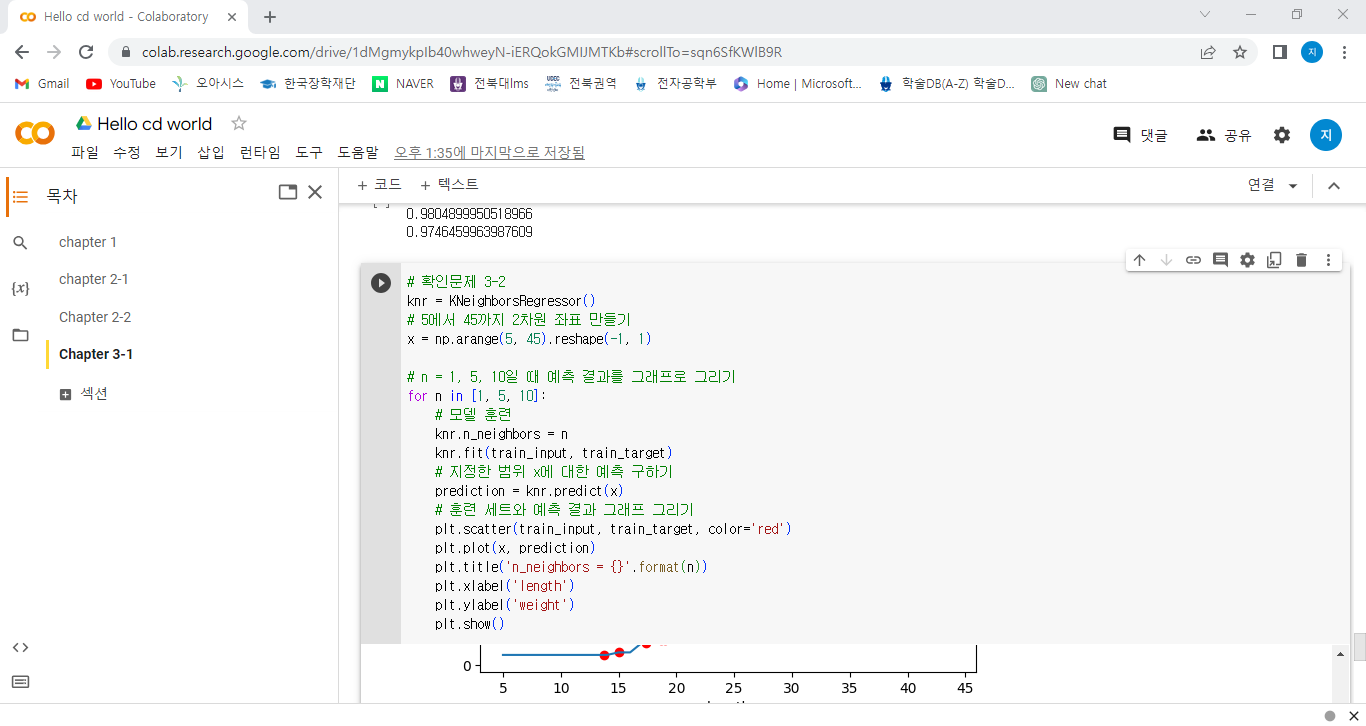
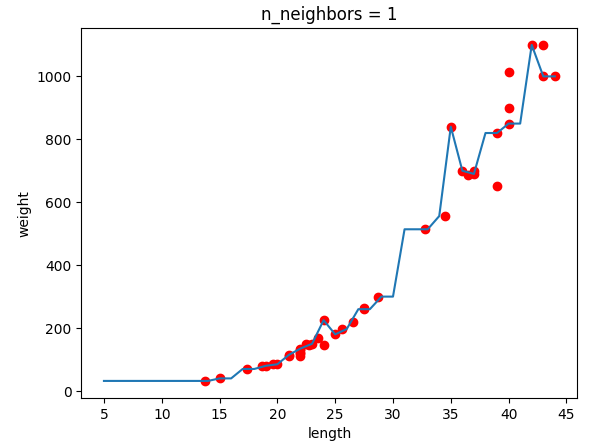
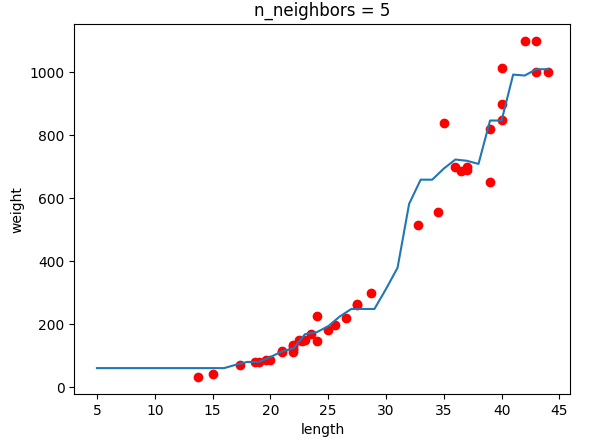
위의 그래프는 N이 1, 5, 10일 때의 KNN 회귀의 모델을 보여준다. 파란선을 확인해보면 N이 커질수록 모델이 단순해진다는 것을 쉽게 알 수 있다.
여기서 KNN 회귀 모델의 치명적인 단점이 존재한다. 훈련 세트의 데이터의 범위를 벗어나는 데이터로 테스트를 한다면 데이터의 거리가 멀어도 근접하다고 판단한 k개의 이웃 데이터로 예측을 수행하기 때문에 우리가 원하지 않는 엉뚱한 값을 예측하게 된다. 그래서 이것의 문제점을 간단하게 해결할 수 있는 선형 회귀가 있다.
선택미션
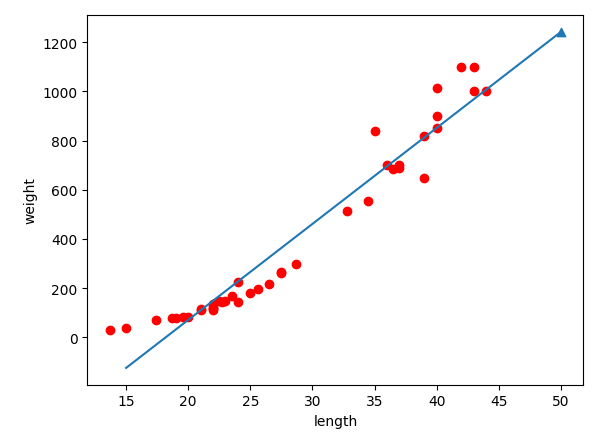
선형 회귀 모델은 위의 그림과 같이 특성에 맞게 직선 혹은 평면 등과 같은 선형 방정식을 찾아 예측을 수행하게 된다. 그래서 앞에서 공부한 KNN 알고리즘처럼 훈련 세트로만 예측을 수행하는 사례 기반 학습 모델이 아닌 선형 회귀는 모델 기반 학습이다. 위의 그림에서 직선의 방정식의 기울기(coef_)와 y절편(intercept_)은 선형 회귀 알고리즘에서 자동적으로 학습한 값인데 이것을 모델 파라미터(model parameter)라고 한다. 선형 회귀 모델에서 계수, 딥러닝 모델에서 가중치 등이 모델 파라미터의 예시이다. 또 다른 파리미터로 하이퍼파라미터(hyperparameter)가 있다. 이것은 경험과 데이터의 특성을 고려한 개발자가 설정한 파라미터로 모델 파라미터와 달리 사용자가 사전에 입력하는 값이다.
'혼공학습단' 카테고리의 다른 글
| 혼공학습단 10기 딥러닝에 대해 알아보자!! 6주차 (0) | 2023.08.20 |
|---|---|
| 혼공학습단 10기 K-평균과 PCA 배워보자 5주차!! (0) | 2023.08.12 |
| 혼공학습단 10기 결정트리와 앙상블 배워보자 4주차!! (0) | 2023.07.23 |
| 혼공학습단 10기 머신러닝 배워보자 3주차!! (0) | 2023.07.15 |
| 혼공학습단 10기 머신러닝 배워보자 (0) | 2023.07.01 |




